


پراکندگی (Sparsity) در علوم داده و یادگیری ماشین: مفاهیم، تاریخچه، کاربردها و مدلها
مقدمه: پراکندگی چیست و چرا مهم است؟
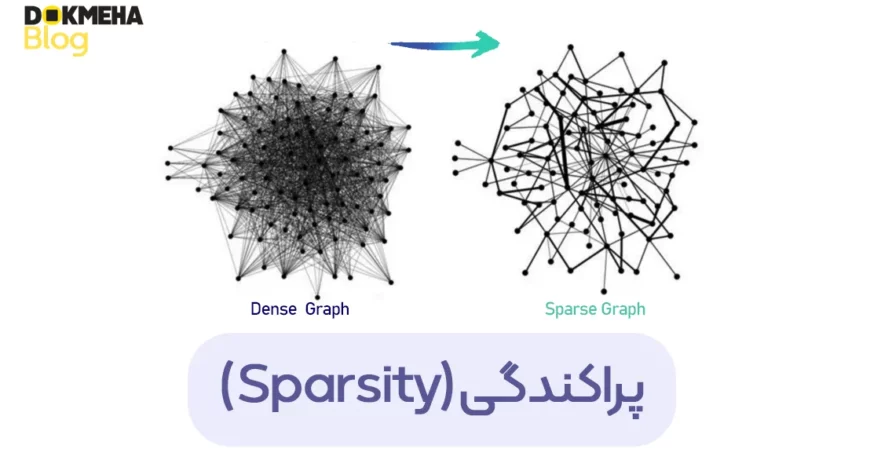
تعریف پراکندگی (Sparsity)
پراکندگی (Sparsity) به حالتی اشاره دارد که بیشتر عناصر یک بردار یا ماتریس برابر صفر هستند یا مقادیر بسیار کوچکی دارند که میتوان آنها را نادیده گرفت. این ویژگی در بسیاری از حوزههای علمی مانند یادگیری ماشین، پردازش سیگنال، بینایی کامپیوتری، بهینهسازی، فشردهسازی دادهها و تحلیل شبکههای اجتماعی اهمیت دارد.
چرا پراکندگی اهمیت دارد؟
در علوم داده و یادگیری ماشین، مدلهای پراکنده کارایی بالاتری دارند، حافظه و پردازش کمتری مصرف میکنند و میتوانند دادههای نویزی را بهتر مدیریت کنند. همچنین، بسیاری از سیستمهای طبیعی مانند مغز انسان، شبکههای اجتماعی و پردازش تصویر بهطور ذاتی دارای خاصیت پراکندگی هستند.
مثال: در یک تصویر دیجیتال، بیشتر پیکسلها دارای مقادیر مشابه هستند و فقط لبهها و ویژگیهای خاص اطلاعات مهم را حمل میکنند، بنابراین پردازش تصویر مبتنی بر پراکندگی میتواند این اطلاعات مهم را استخراج کند.
تاریخچه و مسیر تکامل پراکندگی
آغاز استفاده از پراکندگی
- مفهوم پراکندگی از ریاضیات کاربردی و جبر خطی نشأت گرفته است.
- اولین کاربردهای آن در فشردهسازی دادهها، فیلترهای تطبیقی در پردازش سیگنال و رمزنگاری بوده است.
توسعه در حوزه یادگیری ماشین و پردازش داده
- در دهه ۱۹۹۰، روشهای بهینهسازی مانند LASSO (Least Absolute Shrinkage and Selection Operator) معرفی شد که امکان ایجاد مدلهای پراکنده را فراهم کرد.
- در دهه ۲۰۰۰، تکنیکهای حسگری فشرده (Compressed Sensing) نشان دادند که چگونه میتوان سیگنالهای پراکنده را با نمونهگیری کمتر بازسازی کرد.
- در سالهای اخیر، پراکندگی در شبکههای عصبی عمیق، پردازش زبان طبیعی (NLP) و یادگیری تقویتی نقش مهمی پیدا کرده است.

تأثیر پراکندگی بر تکنولوژیهای دیگر
یادگیری ماشین و هوش مصنوعی
- کاهش تعداد ویژگیها در مدلهای یادگیری ماشین با Feature Selection
- استفاده در Sparse Neural Networks برای کاهش پارامترهای غیرضروری
پردازش تصویر و بینایی کامپیوتری
- بازسازی تصاویر فشرده با Sparse Coding
- حذف نویز از تصاویر و بهینهسازی مدلهای بینایی
فشردهسازی داده و پردازش سیگنال
- استفاده از Compressed Sensing در MRI، رادار و مخابرات
- بهبود روشهای فشردهسازی مانند JPEG و MP3
تحلیل شبکههای اجتماعی و دادههای گرافی
- مدلسازی گرافهای پراکنده برای یافتن روابط مهم
- بهینهسازی الگوریتمهای PageRank و تحلیل ارتباطات
انواع پراکندگی و ویژگیهای آن
دستهبندی پراکندگی از نظر ساختار دادهها
- پراکندگی برداری (Sparse Vectors): بردارهایی که تعداد زیادی مقدار صفر دارند.
- پراکندگی ماتریسی (Sparse Matrices): ماتریسهایی که بیشتر عناصر آن صفر هستند.
- پراکندگی در شبکهها (Sparse Graphs): گرافهایی که دارای تعداد کمی یال هستند.
معیارهای سنجش پراکندگی
- ℓ₀-norm: تعداد عناصر غیرصفر
- ℓ₁-norm: مجموع قدرمطلق مقادیر برای یافتن تخمینهای پراکنده
- Sparsity Ratio: نسبت تعداد صفرها به کل عناصر
مدلهای پراکندگی و کاربردهای آنها
مدلهای پایهای پراکندگی
۱. مدل LASSO (Least Absolute Shrinkage and Selection Operator)
- کاربرد:
انتخاب ویژگی (Feature Selection)
کاهش تعداد پارامترهای مدل در یادگیری ماشین
حذف دادههای غیرضروری
فرمول ریاضی LASSO:
min∣∣Y−Xβ∣∣22+λ∣∣β∣∣1\min ||Y – X\beta||^2_2 + \lambda ||\beta||_1
۲. حسگری فشرده (Compressed Sensing)
- کاربرد:
فشردهسازی تصاویر و دادههای پزشکی (MRI)
بازسازی سیگنالهای صوتی و تصویری
پردازش دادههای مخابراتی
اصل اساسی:
اگر یک سیگنال بهطور طبیعی پراکنده باشد، میتوان آن را با تعداد کمی اندازهگیری بازسازی کرد.
۳. Sparse Autoencoders در یادگیری عمیق
- کاربرد:
کاهش بعد دادهها و بازنمایی ویژگیها
تشخیص ناهنجاری در دادههای بزرگ
مزایا و معایب پراکندگی
مزایا
افزایش سرعت و کارایی مدلها (کاهش تعداد پارامترها)
کاهش نیاز به حافظه و محاسبات
افزایش قابلیت تعمیم مدلهای یادگیری ماشین
قابلیت استفاده در دادههای نویزی و ناکامل
معایب
مشکل در حل مسائل بهینهسازی غیرمحدب
نیاز به انتخاب مناسب مقدار λ در روشهایی مانند LASSO
پیچیدگی در پیادهسازی برخی مدلهای Sparse در یادگیری عمیق
مقایسه مدلهای پراکندگی
| مدل | کاربرد اصلی | مزایا | معایب |
|---|---|---|---|
| LASSO | انتخاب ویژگی | کاهش بعد، تفسیرپذیری بالا | نیاز به تنظیم دقیق λ |
| Compressed Sensing | بازسازی سیگنال | کارایی بالا در فشردهسازی | نیاز به طراحی مناسب ماتریس اندازهگیری |
| Sparse Autoencoders | یادگیری ویژگیهای مهم | بهینهسازی در یادگیری عمیق | نیاز به تنظیمات پیچیده |
آینده پراکندگی و چالشهای پیشرو
اتصال پراکندگی با هوش مصنوعی مولد (Generative AI)
بهینهسازی الگوریتمهای Sparse برای شبکههای عصبی گرافی
توسعه مدلهای جدید یادگیری عمیق با Sparse Representations
نتیجهگیری
پراکندگی (Sparsity) یکی از مفاهیم کلیدی در یادگیری ماشین، پردازش سیگنال و فشردهسازی دادهها است. با وجود چالشهای آن، روشهای پراکنده باعث بهینهسازی کارایی مدلهای هوش مصنوعی، کاهش محاسبات و بهبود تحلیل دادهها شدهاند. پیشرفتهای آینده در Sparse Learning میتواند تأثیر گستردهای بر دنیای علم و فناوری داشته باشد.
نظرات شما چیست؟ آیا تجربهای در استفاده از روشهای پراکنده در یادگیری ماشین یا پردازش سیگنال دارید؟ نظرات خود را با ما به اشتراک بگذارید!

یادگیری ماشین و شبکههای عصبی:
-
«The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks» (2019) – نویسندگان: Jonathan Frankle و Michael Carbin
. این مقاله فرضیه «بلیت بختآزمایی» را مطرح میکند که در شبکههای عصبی متراکم، زیرشبکههای کوچکتری وجود دارند که اگر بهتنهایی آموزش داده شوند میتوانند به دقتی معادل شبکه اصلی برسند
. نویسندگان با هرس کردن شبکههای عصبی پس از آموزش نشان دادند که میتوان بیش از ۹۰٪ اتصالات را بدون کاهش دقت حذف کرد
. آنها زیرشبکههایی را یافتند که تنها با ۱۰٪ تا ۲۰٪ اندازهی شبکه کامل، همان عملکرد را در زمان مشابه یا حتی سریعتر به دست میآورند
. این کار بینش مهمی در مورد اضافهپارامتر بودن مدلهای عمیق ارائه داد و راه را برای فشردهسازی مدلها هموار کرد.
-
«Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding» (2016) – نویسندگان: Song Han, Huizi Mao, William J. Dally
. این پژوهش یک روش فشردهسازی سهمرحلهای برای شبکههای عصبی عمیق ارائه کرده است که شامل هرس وزنهای غیرضروری، کوانتیدهسازی وزنها با دقت پایینتر، و کدگذاری هوفمن است
. نتیجهی این روش کاهش اندازهی مدل به میزان ۳۵ تا ۴۹ برابر بدون افت دقت میباشد
. بهطور مشخص، با حذف اتصالات غیرمهم تعداد پارامترها ۹ تا ۱۳ برابر کاهش و با کوانتیدهسازی تعداد بیت هر وزن از ۳۲ به ۵ بیت تقلیل یافت
. برای مثال، مدل معروف AlexNet از ۲۴۰ مگابایت به ۶٫۹ مگابایت فشرده شد بدون آنکه کاهش دقتی مشاهده شود
. این دستاورد امکان اجرای شبکههای عمیق را در دستگاههای嵌入شده و موبایل با سرعت و بهرهوری انرژی بهتری فراهم میکند.
-
«Learning Sparse Neural Networks through L0 Regularization» (2018) – نویسندگان: Christos Louizos, Max Welling, Diederik P. Kingma
. در این مقاله روشی برای واداشتن شبکههای عصبی به پراکندگی (تنک بودن) در طی مرحلهی آموزش پیشنهاد شده است. این روش با اضافه کردن «دروازههای تصادفی» به وزنها، مستقیماً جریمهی نورم L0 را در تابع هزینه تقریب میزند و بسیاری از وزنها را دقیقاً صفر میکند
. بدین ترتیب شبکه بهطور خودکار تعداد زیادی از اتصالات غیرضروری را حین آموزش حذف میکند که هم سرعت آموزش و آزمون را بهبود میبخشد و هم از بیشبرازش جلوگیری کرده و به تعمیم بهتر کمک میکند
. این رویکرد که با توزیع «سخت-بتن» برای قابل مشتقسازی کردن نورم L0 همراه است، گامی عملی به سوی ساخت مدلهای کوچکتر و بهینهتر در یادگیری عمیق بهشمار میرود.
پردازش سیگنال:
-
-
«Robust Uncertainty Principles: Exact Signal Reconstruction from Highly Incomplete Fourier Information» (2006) – نویسندگان: Emmanuel J. Candès, Justin Romberg, Terence Tao. این مقالهی پیشگام در حوزهی حسگری فشرده (Compressed Sensing) نشان داد میتوان سیگنالهای پراکنده را با نمونهبرداری بسیار کمتر از حد نایکوئیست بازسازی دقیق کرد
. نویسندگان اثبات کردند که تحت شرایطی، حل یک مسئلهی بهینهسازی محدب با نورم L1 معادل حل مسئلهی اصلی با نورم L0 (که NP-سخت است) بوده و منجر به بازیابی دقیق سیگنال تنک میشود
. به بیان ساده، اطلاعات ناکامل فرنئی (مثلاً تعدادی ضرایب پراکنده در حوزهی فرکانس) برای بازسازی کامل سیگنال کافی است. این نتیجه اصول عدم قطعیت کلاسیک را توسعه داد و مبنای نظریهی بازسازی سیگنالهای تنک را بنیان نهاد.
-
«Signal Recovery from Random Measurements via Orthogonal Matching Pursuit» (2007) – نویسندگان: Joel A. Tropp, Anna C. Gilbert. این مقاله یک الگوریتم حریصانه بهنام تعقیب تطبیقی متعامد (OMP) را برای بازسازی سیگنالهای پراکنده معرفی میکند. OMP سیگنال را به صورت گامبهگام تقریب میزند؛ بدین شکل که در هر مرحله برداری از فرهنگ (دایکشِنری) را که بیشترین تطابق با باقیمانده سیگنال دارد انتخاب کرده و در ترکیب سیگنال میگنجاند. Tropp و Gilbert نشان دادند که با وجود سادگی OMP، تحت شرایط معینی این الگوریتم قادر است پشتیبان (محل ضرایب ناصفر) سیگنال را با احتمال بالا به درستی بازیابی کند، مشابه روشهای مبتنی بر بهینهسازی محدب اما با هزینهی محاسباتی کمتر
. این کار OMP را به عنوان یک جایگزین سریع و عملی برای حل مسائل بازسازی سیگنالهای تنک مطرح کرد.
-
«Sparse MRI: The Application of Compressed Sensing for Rapid MR Imaging» (2007) – نویسندگان: Michael Lustig, David L. Donoho, John M. Pauly
. این مقاله کاربرد عملی نظریهی سیگنالهای تنک را در تصویربرداری تشدید مغناطیسی (MRI) نشان میدهد. نویسندگان با ترکیب زیرنمونهبرداری تصادفی دادههای k-space و بازسازی غیرخطی مبتنی بر پراکندگی، توانستند تصویر MRI را با تعداد نمونههای کمتری نسبت به روشهای مرسوم بازسازی کنند.
. تصاویر بازسازیشده کیفیتی قابلمقایسه با تصویربرداری کامل داشتند، در حالیکه سرعت تصویربرداری به طور چشمگیری افزایش یافت. به عنوان مثال، با این روش میتوان دادههای MRI را با کسری از اندازهی معمول دریافت کرده و همچنان تصویری دقیق بهدستآورد که این امر زمان اسکن را کاهش میدهد. این دستاورد نشاندهندهی توان بالقوهی تئوری حسگری فشرده در کاربردهای مهندسی عملی نظیر پزشکی است.
-
آمار و بهینهسازی:
- «Regression Shrinkage and Selection via the Lasso» (1996) – نویسنده: Robert Tibshirani
. در این مقاله روش لاسو (Lasso) معرفی شد که انقلابی در انتخاب متغیرهای مدلهای رگرسیون بهوجود آورد. لاسو با افزودن جریمهی نورم L1 به تابع هزینه رگرسیون خطی، ضرایب مدل را به سمت صفر میل میدهد و برخی از آنها را دقیقاً صفر میکند
. بدین ترتیب، مدل حاصل به طور خودکار تعداد متغیرهای موثر را گزینش کرده و مدل پراکندهای ایجاد میکند که تفسیرپذیری بالاتری دارد. روش لاسو به دلیل توانایی همزمان در کوچکسازی ضرایب و انتخاب ویژگی به یکی از ابزارهای پایهای آمار و یادگیری ماشین برای دادههای ابعادبالا تبدیل شده است.
- «Sparse Inverse Covariance Estimation using the Graphical Lasso» (2008) – نویسندگان: Jerome Friedman, Trevor Hastie, Robert Tibshirani
. این مقاله روش گرافیکال لاسو را برای برآورد ماتریس کوواریانس معکوس (ماتریس دقت) به صورت پراکنده پیشنهاد میکند. ایده اصلی بهکارگیری جریمهی L1 (مشابه لاسو) بر روی مؤلفههای ماتریس کوواریانس معکوس است تا بسیاری از آنها صفر شوند و تنها وابستگیهای مهم بین متغیرها باقی بمانند (یعنی گراف مدل احتمالی به صورت تنک تخمین زده شود)
. نویسندگان با بهکارگیری یک الگوریتم نزول مختصاتی کارآمد، موفق شدند این بهینهسازی را برای مسائل بسیار بزرگ (مثلاً شبکههایی با ۱۰۰۰ متغیر و نیم میلیون پارامتر) در زمانی در حد دقیقه حل کنند
. روش گرافیکال لاسو نسبت به روشهای پیشین ۳۰ تا ۴۰۰۰ برابر سریعتر بود و کاربرد آن را در دادههای واقعی (مانند شبکههای پروتئینی) نشان داد
. این دستاورد امکان تخمین ساختارهای شبکهای تنک را در حوزههایی چون بیوانفورماتیک و اقتصاد بهطور عملی فراهم ساخت.
- «Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers» (2011) – نویسندگان: Stephen Boyd و همکاران
. این مقاله یک مرور جامع و راهنمای عملی برای بهکارگیری روش ADMM (روش ضربکنندههای مجازات به صورت متناوب) در حل مسائل بهینهسازی محدب ارائه میدهد. ADMM یک الگوریتم تقسیمبندی مسئله است که امکان تجزیهی مسائل پیچیدهی بهینهسازی را به زیمسئلههای سادهتر فراهم میکند و بهویژه برای مسائل شامل قیود یا جریمههای غیرمستقیم (مانند جریمهی L1 در مسائل پراکنده) بسیار کارا است. Boyd و همکاران نشان دادند که ADMM چگونه میتواند در حوزههای مختلفی از یادگیری آماری و علوم داده به کار رود – از رگرسیون تنک (لاسو) گرفته تا طبقهبندی و مسائل شبکهای – و ضمن تضمین همگرایی، محاسبات را میتوان به صورت موازی یا توزیعشده انجام داد. این مقاله به دلیل پوشش گسترده و فرمولبندی یک چارچوب統一 برای حل مسائل پراکندگی، تأثیر زیادی بر کاربرد بهینهسازی محدب در یادگیری ماشین و آمار داشته است.